Regression Is Too Much when it leads to overfitting, a common pitfall in statistical modeling where the model learns the training data too well. This results in excellent performance on the training set but poor generalization to new, unseen data. This article explores the causes, consequences, and solutions to overfitting in regression models, helping you understand when “regression is too much.”
Understanding Overfitting in Regression
Overfitting occurs when a regression model is excessively complex, capturing noise and random fluctuations in the training data as if they were true underlying patterns. Think of it like memorizing the answers to a test instead of understanding the concepts. You might ace the practice test, but struggle with the real exam. Similarly, an overfit model performs exceptionally well on the training data but fails to predict accurately on new data. This occurs because the model has essentially “memorized” the training data, including its idiosyncrasies, rather than learning the true relationship between the variables.
Causes of Overfitting
Several factors can contribute to overfitting:
- Too many predictor variables: Using a large number of predictors relative to the number of observations can lead to overfitting, as the model has more freedom to fit the noise in the data.
- Complex model structure: Highly complex models with numerous parameters, such as high-degree polynomials or deep neural networks, are prone to overfitting.
- Insufficient data: With limited data, the model may struggle to distinguish between real patterns and random noise, leading to overfitting.
- Noisy data: Data with significant measurement errors or outliers can mislead the model and encourage overfitting.
Consequences of Overfitting
Overfitting can have serious consequences, particularly when the model is used to make decisions or predictions in real-world applications.
- Poor predictive performance: The primary consequence of overfitting is poor generalization, leading to inaccurate predictions on new data.
- Misleading insights: An overfit model can provide misleading insights into the relationships between variables, as it captures spurious correlations present only in the training data.
- Overestimation of model performance: Evaluation metrics calculated on the training data will be overly optimistic and fail to reflect the true performance of the model.
Detecting Overfitting
Detecting overfitting is crucial for building robust and reliable models. A common technique is to split the data into training and testing sets. The model is trained on the training set, and its performance is evaluated on the unseen testing set. A large discrepancy between the training and testing performance indicates overfitting. Cross-validation, a more sophisticated technique, provides a more robust estimate of model performance by repeatedly training and testing the model on different subsets of the data.
Preventing and Addressing Overfitting
Fortunately, several techniques can prevent or mitigate overfitting:
- Feature selection: Choosing the most relevant predictor variables can reduce model complexity and improve generalization.
- Regularization: Techniques like L1 and L2 regularization penalize large model coefficients, preventing the model from becoming too complex.
- Cross-validation: Using cross-validation to select model hyperparameters can help optimize the model’s ability to generalize.
- Data augmentation: Increasing the size of the training data, either through collecting more data or using techniques like data augmentation, can improve the model’s ability to learn true patterns.
- Pruning: Simplifying complex models, such as decision trees, by removing unnecessary branches can reduce overfitting.
When “Regression Is Too Much”: Practical Examples
Imagine predicting house prices. An overfit model might include irrelevant features like the color of the mailbox or the day of the week the house was listed, leading to inaccurate predictions for new houses. Similarly, in medical diagnosis, an overfit model might focus on noise in patient data, leading to misdiagnoses.
Expert Insights
“Overfitting is a constant challenge in machine learning,” says Dr. Anh Nguyen, a leading data scientist. “It’s essential to understand the trade-off between model complexity and generalization performance.”
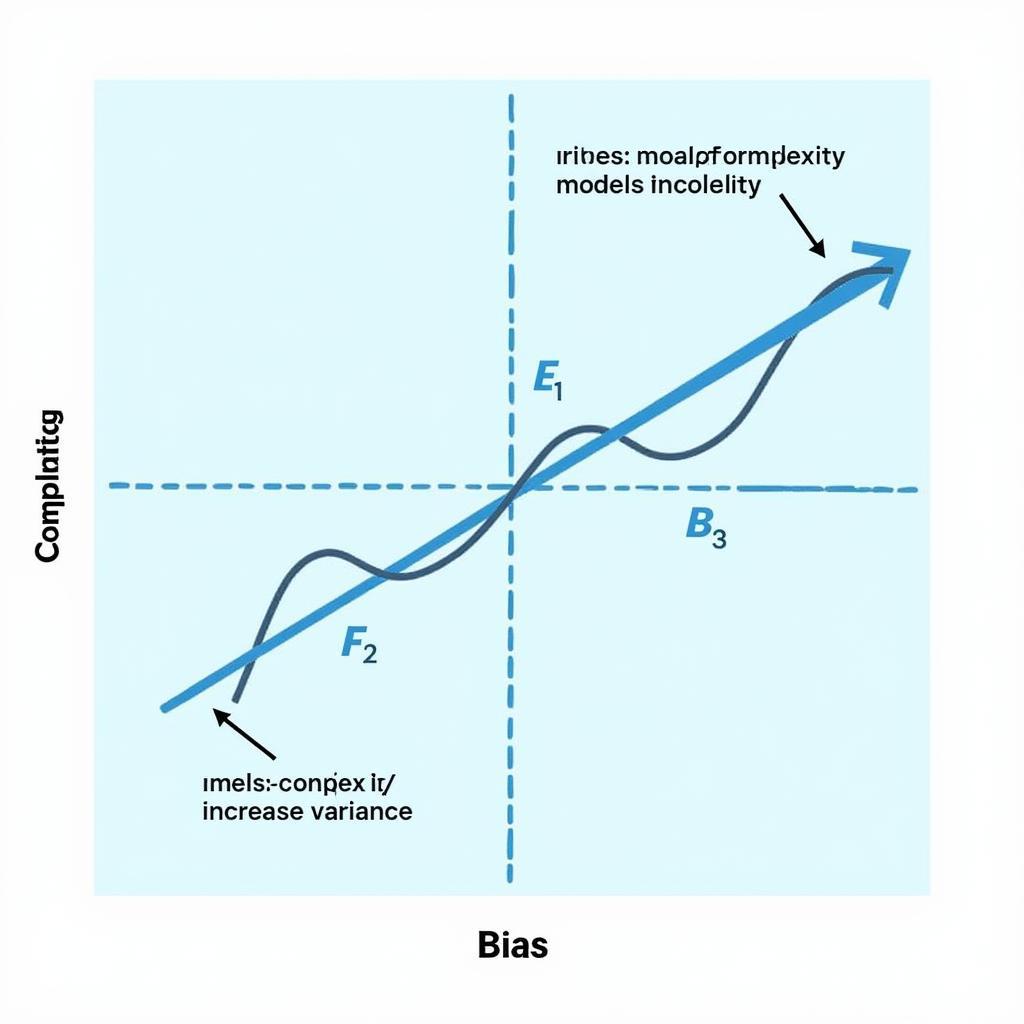 Bias-Variance Tradeoff in Regression
Bias-Variance Tradeoff in Regression
Conclusion
Regression is a powerful tool, but “regression is too much” when it leads to overfitting. By understanding the causes, consequences, and solutions to overfitting, you can build robust and reliable regression models that generalize well to new data, providing accurate predictions and valuable insights. By carefully selecting model complexity, utilizing regularization techniques, and validating model performance, you can harness the power of regression effectively.
FAQs
- What is overfitting in simple terms?
- How do I know if my regression model is overfitting?
- What are the most common causes of overfitting?
- How can regularization help prevent overfitting?
- What is the difference between L1 and L2 regularization?
- What is the role of cross-validation in preventing overfitting?
- What are some real-world examples of overfitting?
Mô tả các tình huống thường gặp câu hỏi.
Người hâm mộ thường hỏi về cách áp dụng các mô hình thống kê trong việc phân tích hiệu suất của Đội Bóng Đá. Vấn đề overfitting thường gặp khi phân tích dữ liệu nhỏ hoặc có nhiễu.
Gợi ý các câu hỏi khác, bài viết khác có trong web.
Xem thêm các bài viết về phân tích dữ liệu bóng đá và machine learning trên website của chúng tôi.